What Is Computer Vision? Tech Explained With Examples

Computer vision is an interdisciplinary scientific field dating back to the 1960s. Almost 60 years later, how far have we come? How does it “mimic the human visual system”, and where can the technology be applied?
With our understanding of vision and innovations in neural networks, some machines can now surpass humans in some tasks, like detecting and labeling objects. Obviously, there is a lot of information to cover, so we’ll start at the basic level.
Let’s dive deep into this fascinating, growing field of study.
Table of Contents
- What Is Computer Vision?
- Distinguishing Computer Vision From Related Fields
- Image Processing
- Machine Vision
- Computer Vision
- Brief History of Computer Vision
- How Does Computer Vision Work?
- 1. Acquiring an Image
- 2. Processing the Image
- 3. Understanding the Image
- Computer Vision Boosted by Deep Learning
- How Long Does It Take to Decipher an Image?
- Applications of Computer Vision
- Industry Applications of Computer Vision
- Current Trends That Drive Commercialized Computer Vision
- AI/Machine Learning Algorithms
- Data Abundance
- Connectivity
- Computational Power
- How Does Computer Vision Help Facial Recognition?
- Limitations of Computer Vision
- What Is the Future of Computer Vision?
- Summary
- FAQ
- What Is Computer Vision and How Does It Work?
- Is Computer Vision Part of AI?
- What Is the Use of Computer Vision?
- Is Computer Vision Accurate?
- What Companies Use Computer Vision?
- What Is Traditional Computer Vision?
What Is Computer Vision?
Computer vision, often abbreviated as CV, trains digital systems to process, analyze, and make sense of the visual world. The concept of computer vision is based on teaching machine learning models how to simulate the way humans see and understand their environment.
Technically, machines attempt to retrieve visual information from images or videos at a pixel level. And through extensive processing, it accurately defines the attributes and eventually identifies and classifies the object. The end goal is not only to have computer vision algorithms that “know” what each object is but also to react to what they “see.”
Of course, the task of imparting human intelligence and instincts to a computer is very complicated. But we’ll try to give a simple explanation to all the aspects going into this process.
Distinguishing Computer Vision From Related Fields
Although the line separating image processing, machine vision, and computer vision is somewhat blurry, there are differences. Before we go any further, let’s clarify what each of the terms means. This will help you understand what computer vision is with more context.
Image Processing
Image processing is mostly related to processing raw images and transforming them without intelligent inference. The algorithm usually performs simple tasks without interpreting the image itself. The task may be smoothing, sharpening, contrasting, rotating, stretching, or reducing noise.
Machine Vision
Machine vision refers to the use of computer vision in real-world interfaces, like industrial environments. One of the most common uses is quality checks.
For example, if used on the production line, machine vision can help manufacturers detect flaws in products before they are labeled and packaged. Or it can detect whether the packaging containers are clean, empty, and free of damage.
Computer Vision
Computer vision is more complex and can be used without a larger machine system. It can analyze large numbers of variables and provide advanced feedback about abstract visual data. For example, it can handle facial recognition or sort objects according to their size. In addition to 2D images, computer vision can be taught to process 3D and moving images.
Brief History of Computer Vision
In 1966, Seymour Papert joined the Artificial Intelligence group at MIT. Together with his colleague Marvin Minsky, they were assigned to the Summer Vision Project. But vision turned out to be one of the most difficult and frustrating challenges in AI. Rudimentary neural networks and algorithms were only developed in the 1980s-90s, but they weren’t remotely powerful enough for computer vision.
Fast forward to 2021, the field of artificial intelligence finally had a breakthrough at the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) – 26% accuracy. The same year, the team at the University of Toronto created a deep neural network called AlexNet with 83.6% accuracy. Artificial intelligence then infiltrated Silicon Valley, and error rates fell to a few percent.
How Does Computer Vision Work?
Let’s break up the process into three main steps.
1. Acquiring an Image

The algorithm needs to be fed large sets of images that can be collected from photos, videos, 3D-made visuals. A good dataset has the following characteristics:
- Quantity – It’s always good to have a lot of data to work with. When it comes to training machine learning models, there are never “too many images”.
- Quality – Images need to be in high resolution. Additionally, they mustn’t have human-generated obscurities like truncation.
- Variance – If we’re talking about cars, there need to be motorcycles, sedans, minivans, SUVs, and trucks. Essentially, there need to be many variations of the object of interest.
- Density – This means that some images need to reflect real-world conditions – for example, other objects on the road.
2. Processing the Image

At this point, the algorithms “look” at the input.
Algorithms enable the machine to learn how to tell one image from another by itself. So, assuming the machine is already trained, the algorithms break down images into pixels, discern hard edges and simple shapes, and run iterations of its predictions. The same applies to videos – the machine understands it as a series of frames.
3. Understanding the Image

Finally, the algorithms interpret the data and accomplish a certain computer vision task, such as image recognition. The output can be a label that describes what’s in the input image, but the parameters are tunable.
Computer Vision Boosted by Deep Learning
Deep learning architectures applied to computer vision produce incredible results, sometimes comparable or even superior to human vision. Deep neural networks, deep belief networks, recurrent neural networks, and convolutional neural networks can all flip the entire process on its head.
Deep learning algorithms don’t rely on clean, structured data for training. If before, traditional supervised machine learning algorithms had to only be fed labeled data, deep learning can produce expected output without the need for manual feature extraction.
Enter the neural network. It is loosely based on human neuron structures – a set of inputs sets off a chain reaction of neurons in the hidden layers. Artificial neural networks (ANN) can have as many as 150 hidden layers (as opposed to 2-3 in machine learning).
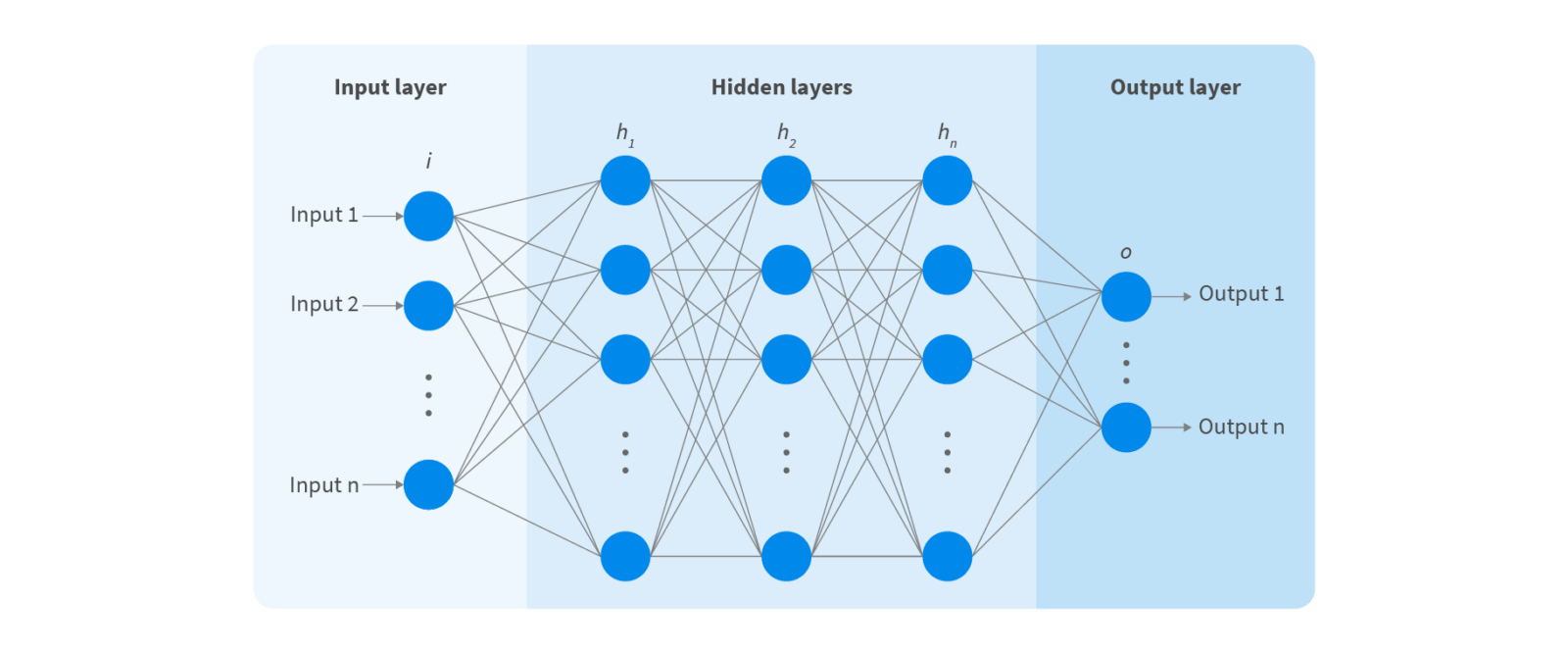
One of the most popular types of ANNs is convolutional neural networks (CNN or ConvNet). A CNN uses 2D convolutional layers to process 2D data, such as images or stills from videos, and to extract features directly from images by itself. This makes deep learning models very efficient for computer vision tasks like object classification.

The first hidden layer can learn how to detect edges, while the last one learns how to recognize more complex shapes. State-of-the-art accuracy has been a major breakthrough for computer vision.
How Long Does It Take to Decipher an Image?
Thanks to top-end processors and all other associated equipment, the process shortened from weeks to minutes and sometimes seconds. The exact time depends on the complexity of the input and the required task.
If you’re not building a system from scratch, you may receive output in 15 minutes. If you’re training the model to decipher images using a massive database, unsurprisingly, it will take longer.
Applications of Computer Vision
Because of the broad amount of problems where we would need a human’s eye to view the situation, lots of computer vision applications have not been discovered or exhausted yet. But the good news is that the collection of useful applications derived from computer vision is rapidly growing. Here are some of them:
- Image classification: A computer first learns a training dataset of labeled images and uses it to classify unlabeled images into distinct categories. It eventually learns the visual appearance of each required class.
- Object detection: This differs from the classification by applying labels to many objects instead of just a single dominant object. For example, in car detection, a computer will detect all cars on an image, along with their bounding boxes.
- Object tracking: This refers to the process of following an object or multiple objects in a given scene. The algorithm observes video and real-world interactions and describes the apparent characteristics.
- Semantic segmentation: It involves dividing whole images into groupings that can be labeled and classified separately. For example, apart from recognizing an object, a computer will also delineate the boundaries of the object.
- Instance segmentation: This process implies segmenting different instances of classes, such as labeling 5 cars with 5 different colors. This is a more complex task since the algorithm needs to identify boundaries, differences, and relations of objects to one another.
Other use cases of computer vision technology are:
- Video motion analysis: Computer vision can detect motion, i.e., find the points where the object is moving, track it over time, group points that belong to the same object in the scene, or calculate the direction and range of the motion.
- Style transfer: This application involves applying a style from one or more images to a new image – for example, the styles of Pablo Picasso or Vincent van Gogh to new photographs.
- Colorization: This means converting a black and white image to a full-color image using existing photo datasets.
- Synthesis: It may involve small modifications of an image/video like adding an object or a face to a scene or generating entirely new images like faces or clothes.
Industry Applications of Computer Vision
Recent developments in computer vision systems have significantly increased their capabilities. This led to rapid adoption by all sorts of companies. Below are industrial sectors that have seen successful use-cases of computer vision and that show growing demand:
- Medical research, diagnostics, and public health
- Technology
- Transportation
- Retail and eCommerce
- Manufacturing and mining
- Banking and financial services
- Security systems and surveillance
- Education
- Law enforcement
- Robotics
- Agriculture
- Automotive
- Fitness and sports
- Real estate
- Many cross-industry applications
Current Trends That Drive Commercialized Computer Vision
There are four main factors that make commercialized computer vision more advanced and, subsequently, more commonly used.
AI/Machine Learning Algorithms
AI/machine learning and computer vision become closely related to one another. While companies spend billions of dollars on buying AI-powered products and services, tech giants spend billions to create those products and services. For computer vision, this has been fantastic news.
The capabilities of intelligent software aren’t capping out any time soon. Some developments are well on their way to being fully realized, while some are merely theoretical. But even what we have now is enough to improve computer vision and offer effective methods for acquisition, image processing, and object focus. AI has also relieved a lot of work in terms of annotating and labeling the data.
Data Abundance
3.2 billion images and 720,000 hours of video are shared online daily. Thanks to social media data, mobile use, and IoT devices, we now have more visual data than ever before. From the perspective of computer vision advances, this is all potential data for learning algorithms. Obviously, not everything can be used as part of a dataset, but the abundance of input is already there.
The more fuel the algorithms receive, the better they become. This ever-going process creates more accurate and effective machines. They also become more accessible, leading to the growing digitization of entire industries.
Connectivity
The world has transitioned to the Internet of Everything, where people, processes, and data are intelligently connected. There are already billions of sensors around the Earth and in its atmosphere sending information back to computers and people for further evaluation and decision-making.
The pervasive access to wireless connectivity created powerful channels for the large-scale exchange of visual data. Computer vision steps in to collect input from connected devices and generate output for a variety of purposes.
Computational Power
The price of computing technologies has decreased dramatically. For example, if a typical worker in 1982 wanted to purchase a machine with the computing power of an iPad2, it would have cost more than 360 years’ worth of wages.
That said, today’s tasks require greater processing power because of greater expectations about performance and because of software requirements. But the last few years showed that most commercial enterprises could afford an entry-level computing instance.
The cheaper the hardware and the software, the more accessible neural network training becomes. And the more common purpose-built neural networks are, the smarter they become.
How Does Computer Vision Help Facial Recognition?
The maturity of the facial recognition industry owes to advances in deep learning and computer vision. The technology can now process thousands of parameters from different faces, but it even goes further.
Rather than looking for a specific set of separate features, the system can recognize the uniqueness of each face’s set of features. It doesn’t look at a face as just a nose, a pair of eyes, and a mouth. Instead, it looks at the combination of features as a whole. This is similar to how humans recognize faces.
From a technological standpoint, facial recognition through computer vision is a real challenge. Experts are still working on improving algorithms using their skills, ingenuity, and huge amounts of datasets. Some even use synthetic images, combining all sorts of color and element variations to strengthen the system.
Limitations of Computer Vision
Despite computer vision outperforming alternative techniques, there are areas of improvement:
- Many vision researchers are biased to work on tasks where the annotation is easy instead of tasks that are important.
- Computer vision powered with deep networks works well on benchmarked datasets but can fail on real-life examples outside the dataset.
- Deep networks are overly sensitive to changes in the image that would not fool a human observer.
- Computer vision can’t understand intent – for example, the difference between extremist propaganda and a documentary about extremist groups.
- True computer vision can only be possible when there is artificial general intelligence, which is still hypothetical.
What Is the Future of Computer Vision?
Deep-learning-based multivariate pattern analysis might be the next step for computer vision. This will improve feature descriptor models and enable comprehensive training protocols for any type of image or data, not just 2D visual data.
As for future applications, the most anticipated ones are:
- Video surveillance: Object and action recognition, behavior determination, crowd analysis, and multiple object tracking will revolutionize the state of video surveillance. But this will also come with privacy concerns.
- Vision-based biometric authentication: Feature-based methods of authentication are already successfully employed. But going forward, vision systems will offer solutions based on direct facial scanning (traditional facial recognition) with the aid of live video input feeds.
- Digital documentation: AI-powered optical character recognition can already extract text from images, bills, financial documents, articles, invoices, and more. What will come in the future is its use in everyday workplaces.
- Facial gesture recognition: Novel algorithms will allow machines to detect emotional states, like happiness, sadness, emotionlessness, and everything in between with higher accuracy.
- Visual question answering: This is a semantic task that asks a text-based question about an image. Computers are still limited in their understanding of the visual world, and this subfield aims to improve that area.
Summary
The application of facial recognition is more than a trend – it is a tool for industries that undergo digital transformation. And given the capabilities of present-day computer vision, it may very soon become a central component in the analytics infrastructure.
Takeaways:
- Computer algorithms aren’t the same as image processing algorithms, but it does rely on image processing algorithms, such as convolutional neural networks.
- The process involves input acquisition, input processing, and output generation.
- The deep learning approach provides much more flexibility and complexity for computer vision than traditional models.
- Computer vision can be used in image classification, object detection, object tracking, instance segmentation, and a lot more.
- There are still limitations when it comes to datasets, intent, and sensitivity to input change.
- Computer vision models are already used in many sectors, but researchers continue to solve computational and processing system inefficiencies.
FAQ
What Is Computer Vision and How Does It Work?
Computer vision is a field of computer science that studies and develops computers and systems capable of capturing and understanding visual inputs. The goal is to let machines derive meaningful information from various digital images and video content. The multi-step process involves acquiring an image/video, processing it, and interpreting it.
Is Computer Vision Part of AI?
It is a subsection of artificial intelligence, But while AI enables computers to “think” and “decide”, computer vision enables them to see, observe, and understand.
What Is the Use of Computer Vision?
In theory, it can be applied to any area where visual input is involved. Some of the more common examples are human identification tasks, detecting events, navigation, modeling objects or environments, and organizing information.
Is Computer Vision Accurate?
In less than a decade, the accuracy of computer systems leaped from below 50% to 99%. In some cases, computers are more accurate than humans at identifying visual inputs because they can amplify certain characteristics like brightness or sharpness. And they certainly react more quickly.
What Companies Use Computer Vision?
Some of the companies that use it are Facebook (Oculus virtual reality technology), Intel (microprocessors, system-on-chip, and multichip packaging products), Axis Communications (security surveillance, remote monitoring, and document management), and Perception (measurement solutions).
What Is Traditional Computer Vision?
Traditional computer vision refers to using commonly known feature descriptors for object detection alongside common machine learning algorithms for prediction. In contrast, the newer approach uses Deep Neural Network architectures. Although DNN is quickly outmuscling traditional vision techniques, it is still used for many image processing tasks.


